
Machine Learning is one of the most popular methods of Artificial Intelligence. Over the past decade, Machine Learning is now one of the essential parts of our life. It is used in a task as easy as recognizing human handwriting or as complicated as self-driving cars.
It is also anticipated that in the near future, the more manual repetitive task will be over. With the increasing amounts of data becoming available there’s a great reason to think that Machine Learning will be a lot more common as a necessary component for technological advancement. There are lots of crucial industries where ML is making a huge impact: Financial services, Delivery, Sales and Marketing, Health Care to name just a few.
K-Nearest Neighbor Algorithm
It is among the simplest Machine Learning algorithms based on Supervised Learning. K-NN algorithm assumes the similarity involving the available cases and the new case and places the new case into the category which is most similar to the available categories.
K-NN algorithm stores all the available data and classify a new data point depending on the similarity. This means when new data appear then it can be classified into a properly suite category by utilizing the K-NN algorithm. K-NN algorithm can be used for Regression at the same time as for Classification but mainly it’s used for the Classification problems.
K-NN algorithm is a non-parametric algorithm, which means it does not make any assumption on underlying data. It is also known as a lazy learner algorithm because it doesn’t learn from the training data set instead it stores the data set and at the time of classification, it then performs an action on the data set. The new input data set is given to the KNN algorithm and it is kept in the category that is much similar to the new data.
Why the KNN algorithm is needed?
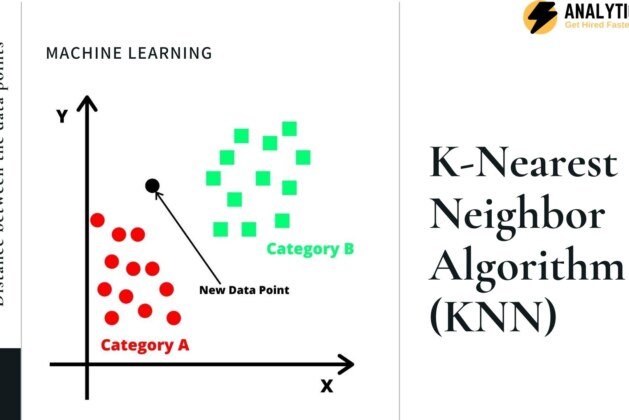
Let us consider, there are two categories A and B, and a new input data point is given x1 and now the question is in which category will this new input data point will be categorized.
To solve this kind of problem we use the KNN algorithm, with this algorithm we can easily identify the category in which the new input data point will fall into. Refer to the image below…
 in Machine Learning 1")
Working of K-NN Algorithm
• Select the K number of the neighbors
• Now calculate the Euclidean distance of K number of neighbors
• As per the calculated Euclidean distance take the K nearest neighbors
• Count the number of the data points in each category among these K neighbors
• Assign the new data points to the category in which the number of neighbors is maximum
• Your model is ready
Now let us suppose that we have a new data point and it needs to be placed in any category based on K-NN algorithm, consider the image below…
 in Machine Learning 2")
• We will choose the number of neighbors, so let us assume K = 5
• Now, we will calculate the Euclidean distance between the data points of both the categories. The Euclidean distance can be calculated as :
 in Machine Learning 3")
• We will get the nearest neighbor by calculating the Euclidean distance, we got 3 neighbors in category A and 2 neighbors in category B. Consider the image below…
 in Machine Learning 4")
• As there are 3 neighbors from category A and 2 from category B, Hence the new data point must belong to category A.
Advantages of KNN Algorithm
• It is very simple to implement
• It acts robustly to the noisy training data
• It is more effective if the training data is large
Disadvantages of KNN Algorithm
• The value of K needs to be determined every time and it can be sometimes complex
• For every training sample, the distance between every data point is calculated and it increases the computational cost.

