
It is a supervised machine learning model that uses classification algorithms for two-group classification problems. After providing an SVM model set of labeled training data for either of 2 groups, they are in a position to categorize new examples.
So you are working on a text classification problem. You are refining your training data, and you have also tried things out using Naive Bayes. But today you are feeling confident in your dataset, and wish to get it one step further. Enter Support Vector Machines (SVM): a quick and reliable classification algorithm that works perfectly with a limited amount of data.
Before going further I guess you have accustomed yourself with linear regression and logistic regression algorithms. If in case not, then I suggest you need to go through them first before going to SVM. Support Vector Machine (SVM) can be used for both regression and classification tasks, but it is mostly used in classification objectives.
To separate the two classes of data points, there can be various possible hyper-planes that could be chosen from. The main objective is to find a plane with the maximum margin, i.e. based on the maximum distance between data points of both the classes. Maximizing the margin distance between the data points of the two classes provides some reinforcement so that new input data points can be classified with more confidence.
Features of Support Vector Machine (SVM) in Machine Learning
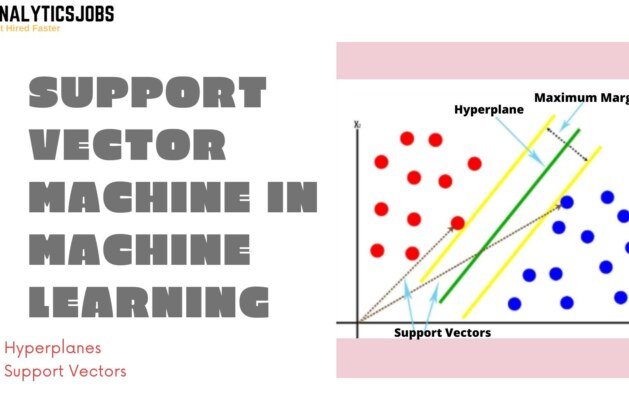
Hyperplanes
Hyperplanes are decision boundaries used to classify the data points. Data points falling on each side of the hyperplane could be linked to different classes. However, the dimension of the hyperplane depends upon the number of characteristics. In case the number of input features is 2, subsequently, the hyperplane is simply a line. When the selection of input features is 3, then the hyperplane gets to be a two-dimensional plane. It becomes hard to picture when the number of features exceeds 3.
 in Machine Learning 1")
Support Vectors
Support vectors are closer to the hyperplane and influence the position and the orientation of the hyperplane. Making use of these support vectors, we maximize the margin of the classifier. Deleting the support vectors are going to change the position of the hyperplane. These are the points that help us develop our SVM.
 in Machine Learning 2")
How do SVM work and types of SVM?
Linear SVM
The fundamentals of Support Vector Machines and how it works are best understood with a basic example. Let us consider 2 tags, red and green, with two planes x and y respectively. We need a classifier that, the given pair of (x, y) coordinates, to determine if the output is either red or blue. In the image given below, we plot our already labeled training data on x and y plane
 in Machine Learning 3")
An SVM takes these data points and outputs a two-dimensional line i.e. the hyperplane that best separates the data points. This line is called the decision boundary: any data point on either side of the line will be the same i.e. it can be either red or blue.
 in Machine Learning 4")
What is the Best Hyperplane?
For SVM, the best hyperplane is the line that maximizes the margins from both the tags or the hyperplane whose distance to the nearest data point of each tag is the largest.
 in Machine Learning 5")
Non-Linear SVM
This example was easy since the given data set was labeled and we were able to draw a straight line between blue and red. Let us now consider that the input data is unlabeled as shown in the figure below…
 in Machine Learning 6")
It is clear that the given input data set is non-linear and a linear decision boundary cannot separate both the tags. However, the next step will be adding a 3rd dimension, till now we had 2 dimension x and y, now we will add a 3rd dimension z and it will be calculated in a certain way that is convenient for us
z = x2 +y2 (equation for a circle)
 in Machine Learning 7")
Now, applying SVM in the above graph:
 in Machine Learning 8")
Note: Since we are in 3D now, the best hyperplane is a plane parallel to the x-axis where suppose z = 1. Then we have to map the 3D to 2D.
 in Machine Learning 9")
How to implement SVM in python?
For implementing machine learning algorithms in Python, scikit-learn is a widely used library and SVM is a part of scikit-learn library and it follows the same structure:
- Import library
- Object creation
- Fitting model
- Prediction
How to implement SVM in R?
In R, to create Support Vector Machines or SVM’s we use the e1071 package. It has helper functions and code for Native Bayes Classifier. To create SVM in python or R similar approaches are followed.
Advantaged of SVM
- With a clear margin of separation, SVM works really well.
- It is effective in cases where the ratio between a number of dimensions is greater than the number of samples.
- It’s effective in high dimensional areas.
- It is a subset of training data points in the decision function and is also known as support vectors, whereas at the same point it is also memory efficient.
Disadvantages of SVM
- It doesn’t perform well when we have a large data set because the required training time of SVM is higher.
- When the target classes are overlapping i.e. the data set contains more noise the SVM doesn’t perform very well.
- SVM never directly provides probability estimates, it is calculated using an expensive 5 fold cross-validation. It is a related SVM method of Python scikit-learn library.

