Classification can be performed on structured and unstructured data. The process of predicting the class of given data points is known as Classification. Classes can be called as targets, labels or categories. Classification predictive modeling is the process of approximating a mapping function (f) from input variables (X) to discrete output variables (y).
For instance, spam detection in e-mail service providers can be recognized as a classification problem. It is binary classification because there are just two classes as spam and not spam. A classifier uses several training data to understand how given input variables are related to the class. With this situation, known spam and non-spam emails have to be used as the training data. If the classifier is trained accurately, it may be used to identify an unknown email.
Classification is a part of supervised learning where the targets are provided with the input data. Classification is in several domains like in credit approval, medical diagnosis, target marketing, etc.
Terminologies used in classifications –
- Classifier – An algorithm used to map the input data in specific categories.
- Classification model – It tries to draw some conclusions from the input data given for training. Then it is used to predict the class labels or categories for the new data.
- Features – It is an individual property of a phenomenon being observed.
- Binary classifications – Classification task with two possible outcomes (True\False).
- Multi-class classifications – Classifications with more than two possible classes. It assigns each sample to one and only one target label. For example, an animal can be a dog or cat but cannot be both at the same time.
- Multi-label classifications – In this type of classification, each sample is mapped to a set of target labels i.e. more than one class. For example, an article can be about sports, a person and location at the same time.
How to build a classification model –
- Initializer – classifier to be used.
- Train the classifier – classifier uses (X, y) method to fit the training model for the given train data X and train label y.
- Predict the target – An unlabeled observation X, the predict X returns the predicted label y.
- Evaluate – the classifier model.
Types of learners in classification –
- Lazy learners – Lazy learners store the training data and wait until testing data appear. When it does, classification is conducted based on the most related data in the saved training data. In comparison to eager learners, lazy learners have less training time but much more time in predicting. Ex, Case-based reasoning, K-nearest neighbor.
- Eager learners – Eager learners built a classification model based on the training data before receiving data for classification. It has to be in a position to commit to a single hypothesis that covers the instance space entirely. As a result of the model construction, eager learners may take a long time to train and less time to predict. Ex, Naïve Bayes, Artificial Neural Network.
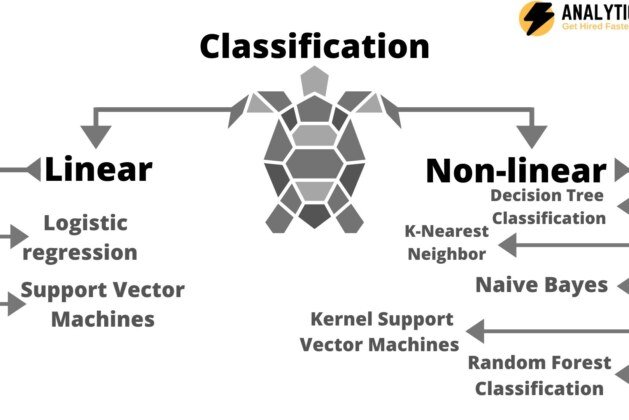
Types of classifications –
- Linear
- Logistic regression
- Support Vector Machines
- Non-linear
- Decision Tree Classification
- K-Nearest Neighbor (KNN)
- Naive Bayes
- Kernel Support Vector Machines (SVM)
- Random Forest Classification